前言
一直以来,我觉得如果可能,尽量把计算放到端设备上,这样会加速整个流程。
这次是使用inception的模型做图像识别。
简介
简单来说,是图形的多分类。
使用的是inception_v3_2016_08_28_frozen.pb这个模型。
想要了解详情,左转搜索inception。
具体流程
简单说:
- 图形转化为输入格式
- 运行模型
- 获取运行结果
因为是图像识别,所以每一步都会麻烦一点。
简单的运行下
这里是输入,百度图片搜索的埃及猫
判定结果

由于这个结果是从0开始的,实际上是287行
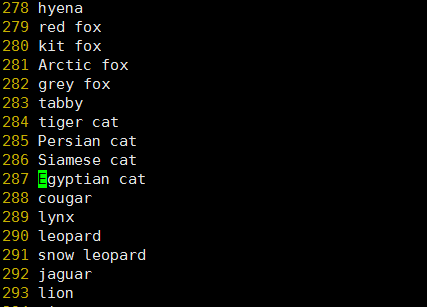
结果是埃及猫,符合输入
总结
撸猫撸猫